
Publications
Preprint




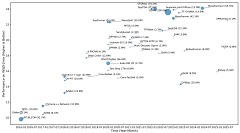

2026



2025







2024





2023




2022


2021




2020






2019




2018



2017


2016

2015
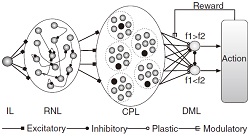
Z. Cheng, Z. Deng, X. Hu, B. Zhang, T. Yang, “Efficient reinforcement learning of a reservoir network model of parametric working memory achieved with a cluster population winner-take-all readout mechanism,” Journal of Neurophysiology, vol.114, no. 6, 3296-3305, 2015.Learning of a reservoir network for working memory of monkey brain. |
 |
X. Li, S. Qian, F. Peng, J. Yang, X. Hu, and R. Xia, "Deep convolutional neural network and multi-view stacking ensemble in Ali mobile recommendation algorithm competition," The First International Workshop on Mobile Data Mining & Human Mobility Computing (ICDM 2015).The team won the Ali competition. Rank 1st over 7186 teams. |
|
M. Liang, X. Hu, B. Zhang, “Convolutional neural networks with intra-layer recurrent connections for scene labeling,” Advances in Neural Information Processing Systems(NIPS), Montréal, Canada, Dec. 7-12, 2015.An application of the recurrent CNN. It achieves excellent performance on the Stanford Background and SIFT Flow datasets. |
 |
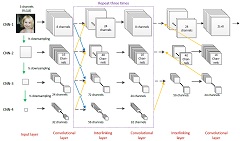
Y. Zhou, X. Hu, B. Zhang, “Interlinked convolutional neural networks for face parsing,” International Symposium on Neural Networks (ISNN), Jeju, Korea, Oct. 15-18, 2015, pp. 222-231.A two-stage pipeline is proposed for face parsing and both stages use iCNN, which is a set of CNNs with interlinkage in the convolutional layers. |
 |
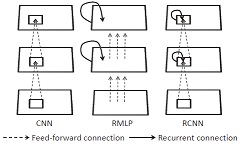
M. Liang, X. Hu, “Recurrent convolutional neural network for object recognition,” Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, June 7-12, 2015, pp. 3367-3375.cuda-convnet2 configs (used in the paper) pytorch version (by Xiao Li) Typical deep learning models for object recognition have feedforward architectures including HMAX and CNN.This is a crude approximation of the visual pathway in the brain since there are abundant recurrent connections in the visual cortex. We show that adding recurrent connections to CNN improves its performance in object recognition. |
 |
X. Zhang, Q. Zhang, X. Hu, B. Zhang, “Neural representation of three-dimensional acoustic space in the human temporal lobe,” Frontiers in Human Neuroscience, vol. 9, article 203, 2015. doi: 10.3389/fnhum.2015.00203Humans are able to localize the sounds in the environment. How the locations are encoded in the cortex remains elusive. Using fMRI and machine learning techniques, we investigated how the temporal cortex of humans encodes the 3D acoustic space. |
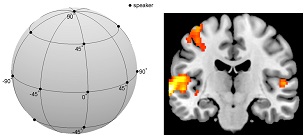 |
M. Liang, X. Hu, “Predicting eye fixations with higher-level visual features,” IEEE Transactions on Image Processing, vol. 24, no. 3, pp. 1178-1189, 2015.There is a debate about whether low-level features or high-level features are more important for prediction eye fixations. Through experiments, we show that mid-level features and object-level features are indeed more effective for this task. We obtained state-of-the-art results on several benchmark datasets including Toronto, MIT, Kootstra and ASCMN at the time of submission. |
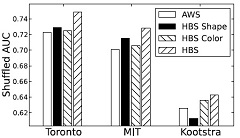 |
M. Liang, X. Hu, “Feature selection in supervised saliency prediction,” IEEE Transactions on Cybernetics, vol. 45, no. 5, pp. 900-912, 2015.(Download the computed saliency maps here) There is a trend for incorporating more and more features for supervised learning of visual saliency on natural images. We find much redundancy among these features by showing that a small subset of features leads to excellent performance on several benchmark datasets. In addition, these features are robust across different datasets. |
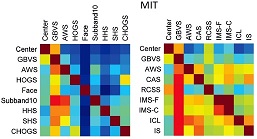 |
Q. Zhang, X. Hu, B. Zhang, “Comparison of L1-Norm SVR and Sparse Coding Algorithms for Linear Regression,” IEEE Transactions on Neural Networks and Learning Systems, vol. 26, no. 8, pp. 1828-1833, 2015.The close connection between the L1-norm support vector regression (SVR) and sparse coding (SC) is revealed and some typical algorithms are compared for linear regression. The results show that the SC algorithms outperform the L1-SVR algorithms in efficiency. The SC algorithms are then used to design RBF networks, which are more efficient than the well-known orthogonal least squares algorithm. |
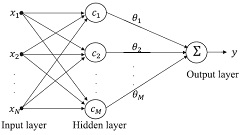 |
2014
T. Shi, M. Liang, X. Hu, “A reverse hierarchy model for predicting eye fixations,” Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, USA, June 24-27, 2014, pp. 2822-2829.We present a novel approach for saliency detection in natural images. The idea is from a theory in cognitive neuroscience, called reverse hierarchy theory, which proposes that attention propagates from the top level of the visual hierarchy to the bottom level. |
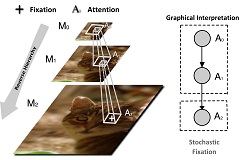 |
X. Hu, J. Zhang, J. Li, B. Zhang, “Sparsity-regularized HMAX for visual recognition,” PLOS ONE, vol. 9, no. 1, e81813, 2014.We show that a deep learning model with alternating sparse coding/ICA and local max pooling can learn higher-level features on images without labels. After training on a dataset with 1500 images, in which there were 150 unaligned faces, 6 units on the top layer became face detectors. This took a few hours on a laptop computer with 2 cores, in contrast to Google's 16,000 cores in a similar project. |
 |
X. Hu, J. Zhang, P. Qi, B. Zhang, “Modeling response properties of V2 neurons using a hierarchical K-means model,” Neurocomputing, vol. 134, pp. 198-205, 2014.We show that the simple data clustering algorithm, K-means can be used to model some properties of V2 neurons if we stack them into a hierarchical structure. It is more biologically feasible than the sparse DBN for doing the same thing because it can be realized by competitive hebbian learning. This is an extended version of our ICONIP'12 paper. |
 |
P. Qi, X. Hu, “Learning nonlinear statistical regularities in natural images by modeling the outer product of image intensities,” Neural Computation, vol. 26, no. 4, pp. 693–711, 2014.This is a hierarchical model aimed at modeling the properties of complex cells in the primary visual cortex (V1). It can be regarded as a simplified version of Karklin and Lewicki's model published in 2009. |
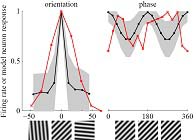 |
2013

2012
20112010200920082007X. Hu and J. Wang, “Solving the k-winners-take-all problem and the oligopoly Cournot-Nash equilibrium problem using the general projection neural networks.” Proc. of 14th International Conference on Neural Information Processing (ICONIP), Kitakyushu, Japan, Nov. 13-16, 2007, pp. 703-712. S. Liu, X. Hu and J. Wang, “Obstacle Avoidance for Kinematically Redundant Manipulators Based on an Improved Problem Formulation and the Simplified Dual Neural Network”, Proc. of IEEE Three-Rivers Workshop on Soft Computing in Industrial Applications, Passau, Bavaria, Germany, August 1-3, 2007, pp. 67-72. X. Hu and J. Wang, “Convergence of a recurrent neural network for nonconvex optimization based on an augmented Lagrangian function,” Proc. of 4th International Symposium on Neural Networks, Part III, Nanjing, China, June 3-7, 2007. 2006X. Hu and J. Wang, “Solving extended linear programming problems using a class of recurrent neural networks,” Proc. of 13th International Conference on Neural Information Processing, Part II, Hong Kong, Oct. 3-6, 2006. |