
Software and Projects
Feature Selection in Supervised Saliency Prediction
Abstract
There is an increasing interest in learning mappings from features to saliency maps based on human fixation data on natural images. These models have achieved better results than most bottom-up (unsupervised) saliency models. However, they usually use a large set of features trying to account for all possible saliency-related factors, which increases time cost and leaves the truly effective features unknown. Through supervised feature selection, we show that the features used in existing models are highly redundant. On each of three benchmark datasets considered in this paper, a small number of features are found to be good enough for predicting human eye fixations in free viewing experiments. The resulting model achieves comparable results to that with all features and outperforms the state-of-the-art models on these datasets. In addition, both the features selected and the model trained on any dataset exhibit good performance on the other two datasets, indicating robustness of the selected features and models across different datasets. Finally, after training on a dataset for two different tasks, eye fixation prediction and salient object detection, the selected features show robustness across the two tasks. Taken together, these findings suggest that a small set of features could account for visual saliency.
Main Results
1. Optimal features
Experiments were performed over the MIT, Toronto and ImgSal datasets. Greedy feature selection (GFS), L1-SVM and AdaBoost were compared and GFS led to the best result. A small proportion of 53 candidate features were selected to yield the optimal feature sets, which consisted of 9, 8 and 9 features for the MIT, Toronto and ImgSal datasets, respectively. The model trained on the optimal sets had comparable performances with the model trained on all features.
| Table I. Feature selection results over three eye tracking datasets. VF denotes valid features. Four metrics, including AUC, NSS, HI and CC were used to evaluate the models. |
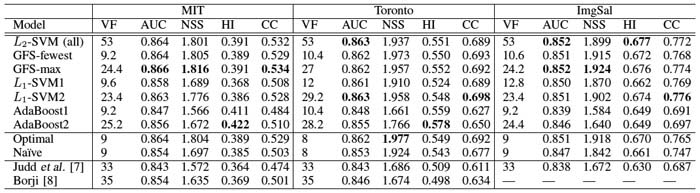
|
2. Robustness across datasets
We then conducted 5-fold cross validation on a dataset with the optimal features for another dataset. In this case, the optimal features for different datasets were swapped (Swap1 condition). The average scores of four metrics were calculated. For better illustration, the scores on each dataset were then normalized by dividing the scores obtained with its own optimal features. Most of the scores were very close to 1 (Fig. 1, top), suggesting that the optimal features were robust across different datasets.
Next, we trained a model on a dataset with its own optimal features and test on the other dataset. In this case, not only the optimal features but also the models (i.e., feature weights) were swapped (Swap2 condition). Even in this case, the performance did not degrade much (Fig. 1, bottom), suggesting that the trained models were robust across different datasets.
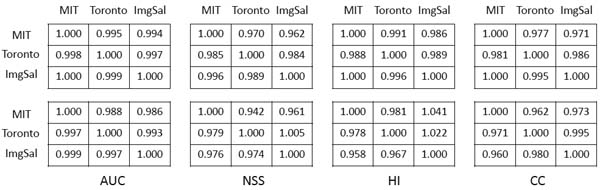
|
| Figure 1. Normalized scores in two swap conditions. Top (Swap1): in each matrix the element on the i-th row and j-th column corresponds to the average score of 5-fold cross validation on dataset i using optimal features for dataset j. Bottom (Swap2): in each matrix the element on the i-th row and j-th column corresponds to the testing score on dataset i with a model trained on dataset j using optimal features for dataset j. All scores in the figure have been normalized by dividing the average score of 5-fold cross validation on dataset i using optimal features for dataset i. |
Download saliency maps
The saliency maps on the three benchmark datasets MIT, Toronto and ImgSal, were calculated with different set of features.
Download from Dropbox
- README.txt
- MITOptimalWithCenter.zip
- TorontoOptimalWithCenter.zip
- ImgsalOptimalWithCenter.zip
- MITAllSaliencyMaps-uint8.mat
- TorontoAllSaliencyMaps-uint8.mat
- ImgsalAllSaliencyMaps-uint8.mat
- MITImgName.mat
- featureName.mat
Download from Baidu cloud (for those who can read Chinese)
- README.txt
- MITOptimalWithCenter.zip
- TorontoOptimalWithCenter.zip
- ImgsalOptimalWithCenter.zip
- MITAllSaliencyMaps-uint8.mat
- TorontoAllSaliencyMaps-uint8.mat
- ImgsalAllSaliencyMaps-uint8.mat
- MITImgName.mat
- featureName.mat
If you encounter any problem in downloading the files, please contact Ming Liang at liangm07@mails.tsinghua.edu.cn
Citation
Ming Liang, Xiaolin Hu, “Feature selection in supervised saliency prediction,” IEEE Transactions on Cybernetics, vol. 45, no. 5, pp. 900-912, 2015.